Simplifying Large-Scale LLM Processing across Instacart with Maple

Author: Paul Baranowski
At Instacart, we’re powering a grocery platform that cuts across millions of items, customers, and deliveries thanks to the application of LLMs at scale. In this post, we’ll detail how LLMs are embedded in critical workflows across the company and span teams and domains. Our engineering teams leverage them to clean up catalog product data, enrich item listings with detailed attributes, assist in routing perishable goods, and even improve search relevance.
For example, the Catalog team uses LLMs to detect and fix data errors, like inaccurate sizes causing tax and pricing losses for Instacart, while enriching listings with new attributes to aid user choices. The Fulfillment team leverages LLMs to help identify perishable items that need special handling during fulfillment. And the Search team trains advanced ranking models with LLMs, enhancing relevance through better query understanding and personalization for superior item matches.
The challenge? Many of these tasks require millions of LLM calls — and real-time LLM provider APIs just aren’t designed for that scale. To address this, we built Maple, a service that makes large-scale LLM batch processing fast, cost-effective (saving up to 50% on LLM costs compared to standard real-time calls), and developer-friendly. With Maple, teams across Instacart can process millions of prompts reliably and efficiently, unlocking new workflows and accelerating development without needing to reinvent infrastructure.
Why We Built Maple
The Catalog team had been developing AI pipelines for some time, and it was becoming increasingly clear that we needed better tooling to support our growing needs. Real-time LLM calls were frequently rate-limited, forcing us to throttle requests to stay within token limits. This introduced delays and made it difficult to keep up with demand. At the same time, multiple teams across the company were independently writing similar code to handle their AI workflows, leading to duplicated effort and fragmented solutions. Our existing pipelines also lacked reusability, as any new use case typically required modifying the underlying code; and as our workloads scaled, we became more conscious of cost and efficiency.
To address these challenges, we decided to build Maple, a reusable service designed to streamline LLM-based workflows. This service was built not just for our team, but for anyone at the company. However, working with the LLM provider’s batch system interface brought its own complexities. Each batch is limited to 50,000 prompts or 200MB, so large jobs, like those with a million prompts, require at least 20 separate batches. Unlike real-time calls, batch workflows have a more involved process: encoding requests in a specific format, uploading them, monitoring job status, downloading result files, parsing them, and retrying failed prompts in new batches. Without shared tooling, each team would be forced to implement this workflow from scratch. Maple solves this by abstracting the complexity and offering a consistent, reusable foundation for scalable AI work.
How Maple Works
Maple accepts a CSV or Parquet file and a prompt as input and delivers an output file with the input merged with the AI response. It automates:
- Batching: Splits large input files into smaller batches.
- Encoding/Decoding: Automates conversions to and from the LLM batch file format.
- File Management: Automates input uploads, job monitoring, and result downloads.
- Retries: Ensures failed tasks are retried automatically for consistent outputs.
- Cost tracking: Tracks detailed cost usage for each team.
By managing these steps, Maple eliminates the need for teams to write custom batch processing code, significantly enhancing productivity.
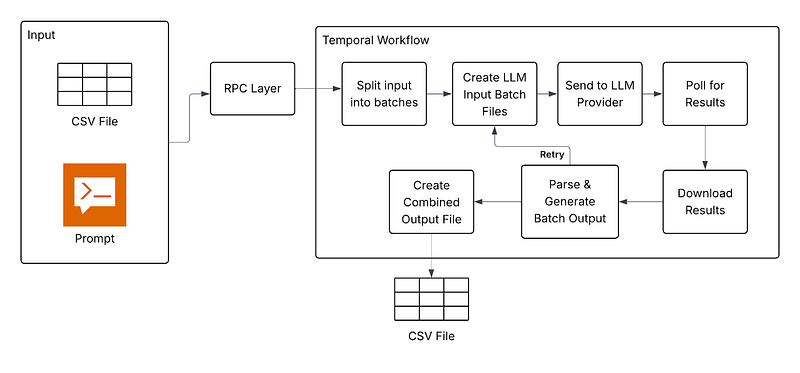
Where Maple Fits in the AI Stack
Maple sits at the center of Instacart’s large-scale LLM processing pipeline, serving as the orchestration layer between internal teams and external model providers.
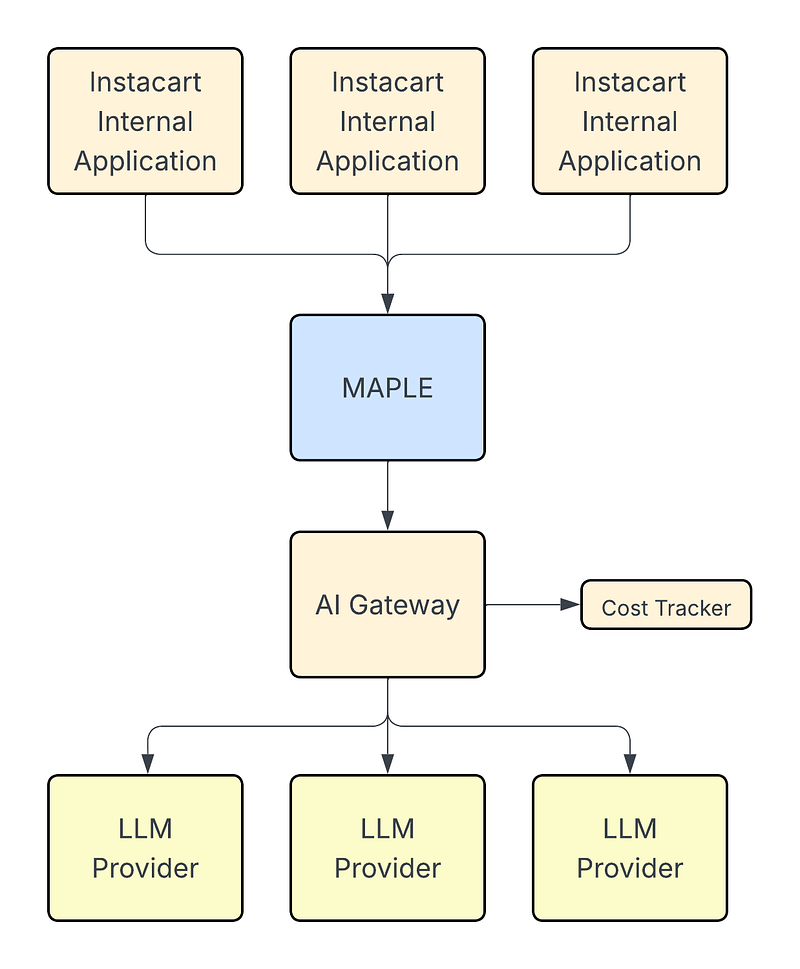
Multiple Instacart internal applications — ranging from product enrichment pipelines to ML training workflows — send prompt data to Maple, which handles all aspects of batching, job coordination, retries, and result merging. From there:
- Maple proxies requests through our AI Gateway, another internal Instacart service which acts as a centralized abstraction layer for communicating with multiple LLM providers.
- The AI Gateway is also responsible for integrating with the Cost Tracker, logging detailed usage and spend per job and team.
- Finally, prompt batches are dispatched to external LLM providers, and results flow back through the same path.
This architecture ensures that teams don’t need to worry about how to call various LLMs and prompt jobs are fully traceable, cost-monitored, and fault-tolerant. By abstracting away complexity, Maple enables faster iteration and experimentation while enforcing consistency and cost controls across the company.
Under the Hood
Maple was designed for scalability and fault tolerance using a combination of modern tools:
- Temporal: Ensures guaranteed completion of long-running tasks. Even if exceptions occur, Temporal’s fault tolerance safeguards data integrity and guarantees job completion.
- RPC API: Provides a streamlined interface for submitting jobs and tracking progress.
- Efficient Storage: Inputs and outputs are stored in S3, avoiding costly database operations. This approach is not only cheaper but also allows handling large datasets.
Implemented in Python, Maple uses PyArrow to efficiently process input files. Large CSV files are split into smaller Parquet batch files, and stored on S3 to avoid costly database usage. Parquet is an efficient file format for data table storage, where out-of-the-box compression reduces file sizes up to 25x compared to CSV. It also allows non-linear access into the file, making data access extremely fast. These batches are converted into the LLM provider batch input format, respecting the max file size cap, which can reduce prompt counts for large prompts.
Maple uploads each file, polls for completion, and when complete, downloads results to S3. It then matches responses to inputs, creating per-batch Parquet result files. Finally, all batch results are combined into a single output file, mirroring the input format.
LLM Batch Processing: How fast is it?
Batch LLM providers say that we should expect results to be returned within 24 hours. In our experience, most of the time batches return relatively quickly, but there are rare periods where there is an obvious delay in processing. We have compiled stats from a sample set of ~580 batches with 40–50K tasks per batch, with most batches having 50K. Below are the real-world results from processing these batches.
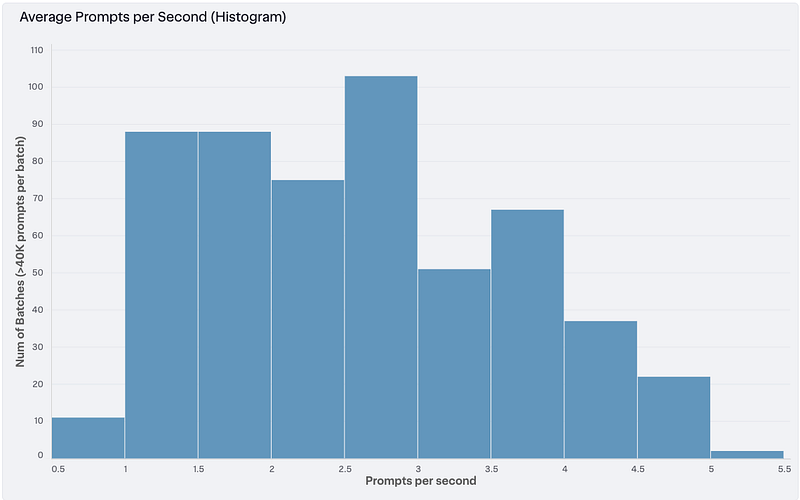
Prompt Processing Speed
The histogram below shows that for a given batch with 40K-50K prompts, how many prompts per second were processed. LLM batches average 2.6 tasks per second. Note that processing time can vary based on the prompt, especially when including images with the prompt, which is a common case for us. We can see that most batches are clustered between 1–4 prompts per second:
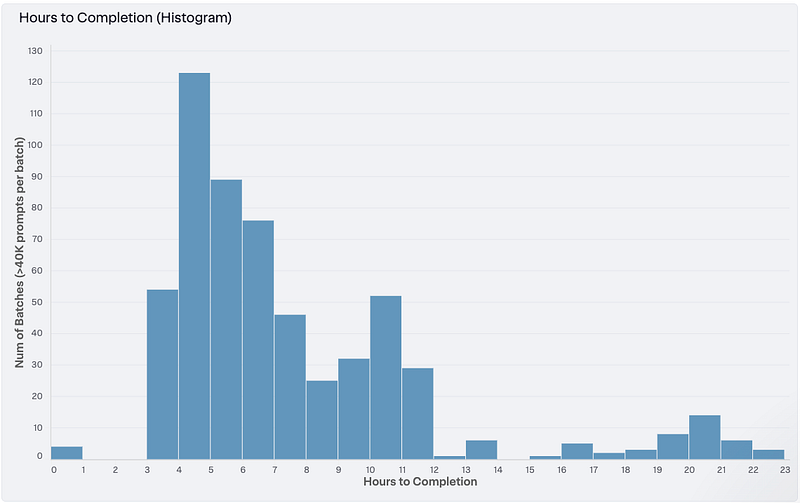
Batch Completion Time
In the histogram below, we can see that most batches complete in under 12 hours, with occasional batches that take almost a full day:
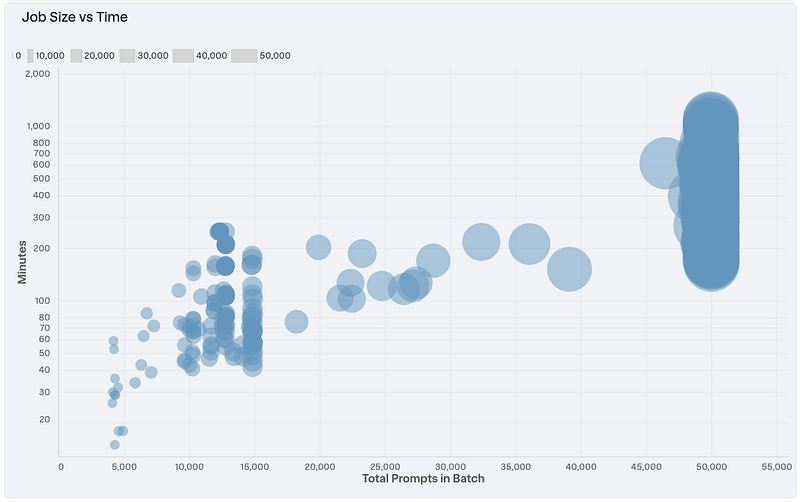
Job Size vs Time
In the scatter plot below, we can see that the time to complete a batch job increases with the number of tasks in the job, as you would expect. Note the log scale on the Y-axis.
Lessons Learned
Building Maple to handle tens of millions of prompts reliably and efficiently required a lot of iteration. Here are some of the key lessons we learned while scaling the system and making it robust enough for widespread use across Instacart.
Optimizing for High-Volume Workloads
As our internal clients sent larger and larger input files, we hit storage, memory, and processing limitations. To address this:
- We moved task data storage from the database to S3 using Parquet files, which improved load/save speed and reduced cost.
- We adopted stream-based processing to minimize memory consumption when handling large files.
- We replaced some of Python’s built-in libraries, such as the ‘json’ library with ‘orjson’, a faster and more memory-efficient alternative.
These optimizations allowed Maple to scale efficiently to 10M+ prompt jobs.
Ensuring Reliable Execution
Running batch jobs at this scale means errors are inevitable — network issues, provider failures, or bugs can happen mid-run. We use the Temporal durable execution engine to ensure that jobs can resume exactly where they left off without losing any work. This not only protects against data loss but also avoids wasting money on partially completed jobs.
Handling Failure Modes Gracefully
LLM providers return various types of task-level failures, each requiring tailored handling logic:
- Expired: Occasionally, the LLM provider fails to return results within 24 hours and it will return an error/expired message with no result for that task. Maple will retry these infinitely by default by constructing a new batch with the failed tasks.
- Rate limited: When we hit the LLM provider token limit, it will return an error message with no result for that task. We retry these infinitely by default.
- Refused: The LLM provider can just refuse to execute your request — can be because of bad parameters, or the image/prompt being filtered (ie. unacceptable). We retry these for a max of two times by default, because it will probably return the same result.
- Invalid images: Sometimes the requests have an image URL that is invalid. The endpoint might not exist or the image might not be available. In this case, your request could fail. We provide an option to retry these, but the second time around, Maple will check if the image exists before sending it back to our LLM provider. We don’t do this the first time around because checking each image in a large batch can add significant overhead.
Building a Robust Foundation
These lessons helped shape Maple into a resilient, high-throughput batch processing system. By building in fault tolerance, efficient processing, and robust failure handling, we enabled any team at Instacart to run massive LLM workloads without needing to build their own infrastructure — or worry about what happens when things go wrong.
Extending Maple to Additional LLM Providers
Not all LLM providers offer a batch interface, some only support real-time APIs. As internal teams requested access to these additional providers, we extended Maple to abstract the complexity of handling large-scale real-time prompts while maintaining our simple CSV input/output interface.
Behind the scenes, we implemented automatic parallelization, exponential backoff on rate-limited requests, intelligent retry policies, and failure tracking — all the same operational maturity we applied to batch file-based workflows. Later on, if a provider starts offering a batch interface, we can switch it over seamlessly without our users needing to do anything.
Teams no longer need to write custom scripts or pipelines to handle bulk real-time calls. Instead, they can use the same Maple interface, and the underlying platform will handle the complexities of interacting with real-time APIs at scale. Enabling real-time support also had the additional benefit of making small batches complete more quickly, which is important for ops-related tasks when they are iterating on a problem.
Adoption and Impact
Maple has become part of the backbone of our AI infrastructure at Instacart, with several different teams leveraging it as a universal bulk LLM provider. It has dramatically reduced costs by automating repetitive, manual tasks, freeing up teams to focus on higher-impact work. Many processes have been reduced from hundreds of thousands of dollars per year to just thousands of dollars per year.
Maple democratizes access to bulk LLM prompt processing at Instacart. Teams can now explore new ideas, automate repetitive work, and ship faster — without becoming LLM infrastructure experts. By simplifying bulk prompting, it accelerates innovation, lowers costs, and ultimately provides new features to our customers.
Instacart
Author
Instacart is the leading grocery technology company in North America, partnering with more than 1,800 national, regional, and local retail banners to deliver from more than 100,000 stores across more than 15,000 cities in North America. To read more Instacart posts, you can browse the company blog or search by keyword using the search bar at the top of the page.